
OpenAI API学习及Function Calling
0. 前言
虽然也做了一端时间的大模型智能体开发工作,但是一直用的LangGraph框架,对一些API细节和工具调用的流程一直是云里雾里的,只知道模板(开源项目)是这样写的,照着复制就行了,能跑就行。趁着最近工作不是很忙,重新学习理解了一些细节,对工具调用的流程也有了新的认识。
用的模型是qwen,所以我主要是针对OpenAI API进行学习。参考自百炼平台的API参考大模型服务平台百炼控制台和官方文档如何通过Function Calling 实现工具调用-大模型服务平台百炼(Model Studio)-阿里云帮助中心
1. Chat API细节
使用OpenAI原生Chat API后,感觉整个智能体项目都变得更加简洁了,大模型交互的流程也更加清晰了,可能比较适合像我这样的初学者吧。详细的API信息可以去查帮助文档,本文只对一些以前掌握不清的Chat API概念进行记录讲解,不做过多细化。
1.1. 请求体messages消息类型
请求体API包含用户提的问题和对模型具体参数进行调节的内容。数组messages中的内容是传递给大模型的上下文,按对话顺序排列。其类型分为:System、User、Assistant、Tool,其中User类型的消息是必须给的,其他三种消息都是可选。
调用模型时,需构造一个由上述消息对象构成的数组messages。一个典型的请求通常由一条定义行为准则的 system 消息和一条用户提指令的 user 消息组成。
system消息是可选的,但建议使用它来设定模型的角色和行为准则,以获得更稳定、一致的输出。
messages: array
[
{"role": "system", "content": "你是一个有帮助的助手。"},
{"role": "user", "content": "你是谁?"}
]输出的响应对象中会包含模型回复的assistant消息。
{
"role": "assistant",
"content": "你好!我是Qwen!"
}System Messageobject: 系统消息,用于设定大模型的角色、语气、任务目标或约束条件等。一般放在messages数组的第一位。包含以下属性:contentstring: 系统指令,用于明确模型的角色、行为规范、回答风格和任务约束等rolestring: 系统消息的角色,固定为system
User Messageobject: 用户消息,用于向模型传递问题、指令或上下文等。包含以下属性:contentstring: 消息内容。若输入只有文本,则为 string 类型;若输入包含图像等多模态数据,或启用显式缓存,则为 array 类型rolestring: 用户消息的角色,固定为user
Assistant Messageobject: 模型的回复。通常用于在多轮对话中作为上下文回传给模型。包含以下属性:contentstring: 模型回复的文本内容。包含tool_calls时,content可以为空;否则content为必选rolestring: 助手消息的角色,固定为assistantpartialboolean: 是否开启前缀续写。默认值为falsetool_callsarray: 发起Function Calling后,返回的工具与入参信息,包含一个或多个对象。由上一轮模型响应的tool_calls字段获得。包含以下内容:idstring: 工具响应的IDtypestring: 工具类型,当前只支持设为functionindexinteger: 当前工具信息在tool_calls数组中的索引functionobject: 工具与入参信息。包含以下内容:namestring: 工具名称argumentsstring: 入参信息,为JSON格式字符串
Tool Messageobject: 工具的输出信息。包含以下属性:contentstring: 工具函数的输出内容,必须为字符串。若工具返回结构化数据(如JSON),需将其序列化为字符串rolestring: 固定为tooltool_call_idstring: 发起Function Calling后返回的 id,通过completion.choices[0].message.tool_calls[$index].id获取,用于标记Tool Message对应的工具
1.2. 模型部分参数
在请求体中还可以对模型的部分参数进行指定,从而调整模型的生成内容。
- temperature float: 采样温度,控制模型生成文本的多样性。
- temperature 越高,Token 概率分布变得更平坦(即高概率 Token 的概率降低,低概率 Token 的概率上升),使得模型在选择下一个 Token 时更加随机。
- temperature 越低,Token 概率分布变得更陡峭(即高概率 Token 被选取的概率更高,低概率 Token 的概率更低),使得模型更倾向于选择高概率的少数 Token
- temperature越高,生成的文本更多样,反之,生成的文本更确定
- 取值范围: [0, 2)
- temperature与top_p均可以控制生成文本的多样性,建议只设置其中一个值
- top_p float: 核采样的概率阈值,控制模型生成文本的多样性。
- top_p 采样是指从最高概率(最核心)的 Token 集合中进行采样。它将所有可能的下一个 Token 按概率从高到低排序,然后从概率最高的 Token 开始累加概率,直至概率总和达到阈值(例如80%,即 top_p=0.8),最后从这些概率最高、概率总和达到阈值的 Token 中随机选择一个用于输出
- top_p 越高,考虑的 Token 越多,因此生成的文本更多样
- top_p 越低,考虑的 Token 越少,因此生成的文本更集中和确定
- 取值范围:(0,1.0]
- top_k integer: 指定生成过程中用于采样的候选 Token 数量。值越大,输出越随机;值越小,输出越确定。
- 若设为
null或大于 100,则禁用top_k策略,仅top_p策略生效 - 取值必须为大于或等于 0 的整数
- 若设为
- presence_penalty float: 控制模型生成文本时的内容重复度。
- 取值范围:[-2.0, 2.0]。正值降低重复度,负值增加重复度
- 在创意写作或头脑风暴等需要多样性、趣味性或创造力的场景中,建议调高该值;在技术文档或正式文本等强调一致性与术语准确性的场景中,建议调低该值
- max_tokens integer: 用于限制模型输出的最大 Token 数。若生成内容超过此值,生成将提前停止,且返回的
finish_reason为length。- 默认值与最大值均为模型的最大输出长度
- 适用于需控制输出长度的场景,如生成摘要、关键词,或用于降低成本、缩短响应时间
- 触发
max_tokens时,响应的 finish_reason 字段为length max_tokens不限制思考模型思维链的长度
- n: 生成响应的数量。
- 取值范围是
1-4 - 适用于需生成多个候选响应的场景,例如创意写作或广告文案
- 取值范围是
- enable_thinking: 使用混合思考(回复前既可思考也可不思考)模型时,是否开启思考模式
- 开启后,思考内容将通过
reasoning_content字段返回
- 开启后,思考内容将通过
1.3. 模型响应
对于非流式输出(如智能体调用模型的时候),经常可以看到提取模型的响应内容的代码 assistant_message = response.choices[0].message,以前由于不了解响应内容的具体格式,对这个代码也只停留在表面。
OpenAI API的大模型响应格式为:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "我叫千问。"
},
"finish_reason": "stop",
"index": 0,
"logprobs": null
}
],
"object": "chat.completion",
"usage": {
"prompt_tokens": 3019,
"completion_tokens": 104,
"total_tokens": 3123,
"prompt_tokens_details": {
"cached_tokens": 2048
}
},
"created": 1735120033,
"system_fingerprint": null,
"model": "qwen-plus",
"id": "chatcmpl-6ada9ed2-7f33-9de2-8bb0-78bd4035025a"
}其中,choices属性比较重要,涉及到了模型输出信息和工具调用信息。
choicesarray: 模型生成内容的数组,表示模型生成的可能的输出选项。通常情况下,列表中只有一个元素(即choices[0]),除非在调用时指定了生成多个候选输出。其成员属性有:finish_reasonstring: 模型停止生成的原因。有三种情况:- 触发输入参数中的
stop参数,或自然停止输出时为stop - 生成长度过长而结束为
length - 需要调用工具而结束为
tool_calls
- 触发输入参数中的
indexinteger: 当前对象在choices数组中的索引logprobsobject: 模型输出的 Token 概率信息messagesobject: 模型输出的消息。包含:contentstring: 模型的回复内容reasoning_contentstring: 模型的思维链内容refusal: nullrolestring: 消息的角色,固定为assistantaudio: nulltool_callsarray: 在发起 Function Calling后,模型生成的工具与入参信息,包含以下内容:idstring: 本次工具响应的唯一标识符typestring: 工具类型,当前只支持functionindexinteger: 当前工具在tool_calls数组中的索引functionobject: 工具信息namestring: 工具名称argumentsstring: 入参信息,为JSON格式字符串。由于大模型响应有一定随机性,输出的入参信息可能不符合函数签名。请在调用前校验参数有效性
因此:
提取大模型的回复信息:response.choices[0].message
从回复信息中再提取工具调用信息:response.choices[0].message.tool_calls
从工具调用信息中提取工具参数:response.choices[0].message.tool_calls[n].function.name or arguments,注意tool_calls为一个数组,所以需要对其进行索引遍历,可以使用for tc in tool_calls来对每个工具进行遍历执行。
2. Function Calling实现细节
以下是我个人对大模型智能体Function Calling实现方法的理解。
用户通过在发送给大模型的请求体中添加tools数组,让大模型知道了哪些工具可供使用,根据tools API对工具对象的要求,构建出来的tools数组工具对象成员的形式一般如下所示:
{
"type": "function",
"function": {
"name": "bash",
"description": "运行 shell 命令。",
"parameters": {
"type": "object",
"properties": {
"command": {"type": "string", "description": "要执行的命令"}
},
"required": ["command"],
"additionalProperties": False
},
},
},
{
"type": "function",
"function": {
"name": "read_file",
"description": "读取文件内容。",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "文件路径"},
"limit": {"type": "integer", "description": "最大行数限制"}
},
"required": ["path"],
"additionalProperties": False
},
},
}整个Function Calling的流程为:
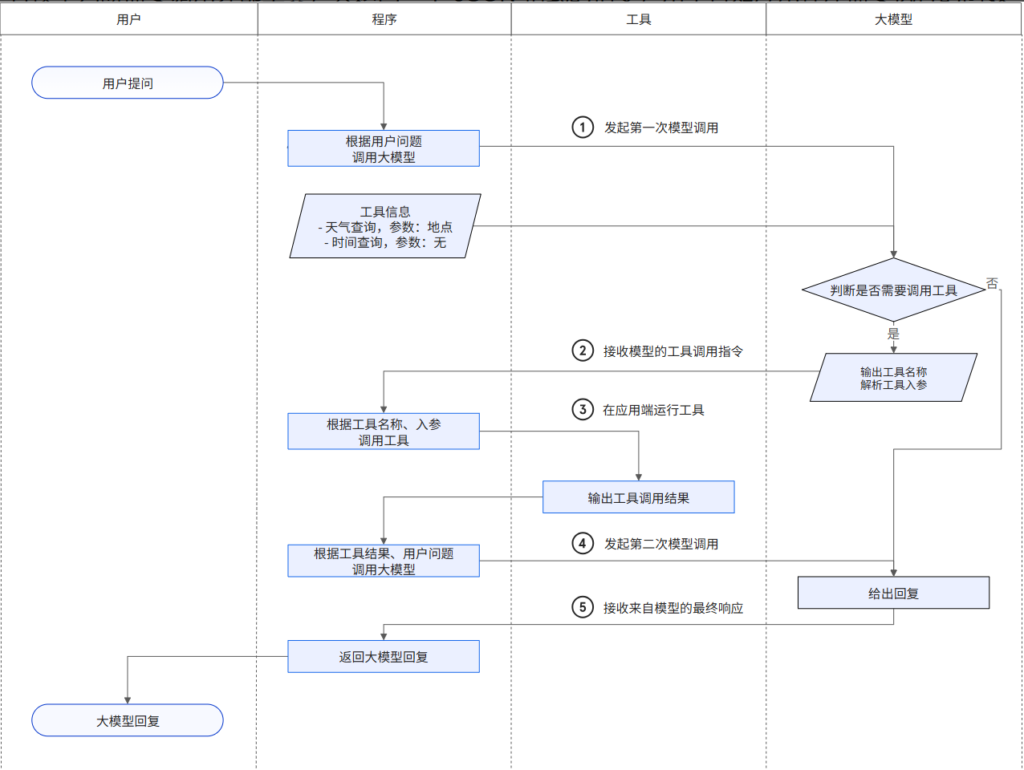
首先,用户输入问题,应用程序首先向大模型发起一个包含用户问题的上下文messages(第一次调用时messages仅包含system提示词和用户输入的问题)与模型可调用工具清单的请求。这个应用程序也就是智能体程序 or 大模型交互程序等。
然后,大模型根据上下文内容,参考外部工具信息,判断是否需要使用工具。若模型判断需要调用外部工具,会返回一个JSON格式的指令,用于告知应用程序需要执行的函数与入参;若模型判断无需调用工具,会返回自然语言格式的回复。
接下来,应用程序解析大模型的回复内容response.choices[0].message,提取response.choices[0].message.tool_calls,判断tool_calls数组是否为空,若为空,则说明大模型没有调用工具,此时直接输出大模型的回复内容即可结束交互循环;若不为空,则遍历tool_calls数组,将每个被大模型认为需要调用工具成员中的工具名称(即tool_calls[n].function.name)、工具参数(即tool_calls[n].function.arguments)提取出来,由应用程序来运行对于的工具(一般有一个工具统一调用接口,传入工具名和参数,即可运行相应的工具函数),获得工具输出结果。
然后,在获取到工具输出结果后,将大模型在第一次调用时输出信息(可能为空)和大模型请求调用的工具列表(工具调用id、名称、参数等)作为一个整体,以assistant的角色添加到上下文messages中,然后将每个工具的输出结果(由于工具是遍历tool_calls数组依次执行的,故工具输出结果也是依次以tool角色添加到了results数组中)使用extend方法添加至模型的messages中,此时,messages包含:1. system提示词;2. 用户提问;3. 大模型回复+工具调用结果。用这个越来越长的messages再次发起模型调用:
# 在工具调用循环中:
results.append({
"role": "tool",
"tool_call_id": tc.id,
"content": output
})
tc = response.choices[0].message.tool_calls[n]
messages.append({
"role": "assistant",
"content": response.choices[0].message.content,
"tool_calls": [
{
"id": tc.id,
"type": "function",
"function": {
"name": tc.function.name,
"arguments": tc.function.arguments
}
}
for tc in tool_calls
]
})
messages.extend(results)⚠️ tool_call_id 必须与对应的 tool_calls[].id 完全一致,否则模型无法正确关联请求和结果!
最后不断循环,直到大模型不再调用工具(返回对象中包含回复内容content而tool_calls参数为空),模型将工具输出结果和用户问题信息整合,生成自然语言格式的回复,退出循环,结束本次对话。
更多细节(如并行工具调用、强制工具调用)可参考:如何通过Function Calling 实现工具调用-大模型服务平台百炼(Model Studio)-阿里云帮助中心


