Qwen3-Reranker模型在Jetson AGX Orin上python部署
0. 前言
为了提高给知识库系统检索质量,准备增加一个reranker模型,出于对Qwen的信赖(主要是大模型和embedding模型都选用的Qwen),选择了Qwen3-Reranker-8B模型进行部署。模型介绍及下载参考www.modelscope.cn/models/Qwen/Qwen3-Reranker-8B
1. Jetson pytorch环境
由于一些硬件原因,Reranker模型准备部署到Nvidia的AI开发套件Jetson AGX Orin上,该套件是arm架构,集成显卡iGPU,NVIDIA Jetson 系列是 SoC(片上系统)架构,CPU 和 GPU 封装在同一块芯片上。这里的 GPU 就是“集成显卡”(相对于电脑中独立的 PCIe 显卡而言)。Jetson 系列没有独立的显存,CPU 和 GPU 共享同一块物理内存条,当 GPU 需要加载模型权重、输入图像数据或中间计算结果时,它会从系统总内存中划拨一部分作为自己的“显存”使用。这部分被占用的内存就是 GPU Shared RAM。
因此不能直接pip install torch,比较简单的方法是使用Nvidia的官方pytorch镜像
首先,检查开发套件的软件配置:
cat /etc/nv_tegra_release
# R36 (release), REVISION: 4.4, GCID: 41062509, BOARD: generic, EABI: aarch64, DATE: Mon Jun 16 16:07:13 UTC 2025
# KERNEL_VARIANT: oot
TARGET_USERSPACE_LIB_DIR=nvidia
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Wed_Aug_14_10:14:07_PDT_2024
Cuda compilation tools, release 12.6, V12.6.68
Build cuda_12.6.r12.6/compiler.34714021_0
| 字段 | 值 | 含义解读 |
|---|---|---|
| R36 | R36 | JetPack 6.x 系列 (基于 Ubuntu 22.04) |
| REVISION | 4.4 | L4T (Linux for Tegra) 36.4.4 对应 JetPack 6.1 (或 6.1 的某个补丁版本) |
| BOARD | generic | 通用板型配置 (常见于开发套件或自定义载板) |
| EABI | aarch64 | 64位 ARM 架构 (确认是 Orin/Nano 等现代芯片) |
| DATE | Jun 16 2025 | 镜像构建时间 |
在Nidia网站docs.nvidia.com/deeplearning/frameworks/install-pytorch-jetson-platform-release-notes/pytorch-jetson-rel.html#pytorch-jetson-rel查询可知,JetPack6系列最新的pytorch镜像是25.06(这一步其实我也没搞懂到底是哪个版本,所以下载了6系列的最新版本)。
前往Nvidia的官方镜像网站catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch/tags?version=25.06-py3,找到对应版本的镜像进行pull,需要注意的是,Jetson AGX Orin是集成显卡iGpu,需要注意区分,下载后缀igpu的版本,不然会出现CUDA error: no kernel image is available for execution on the device的报错。
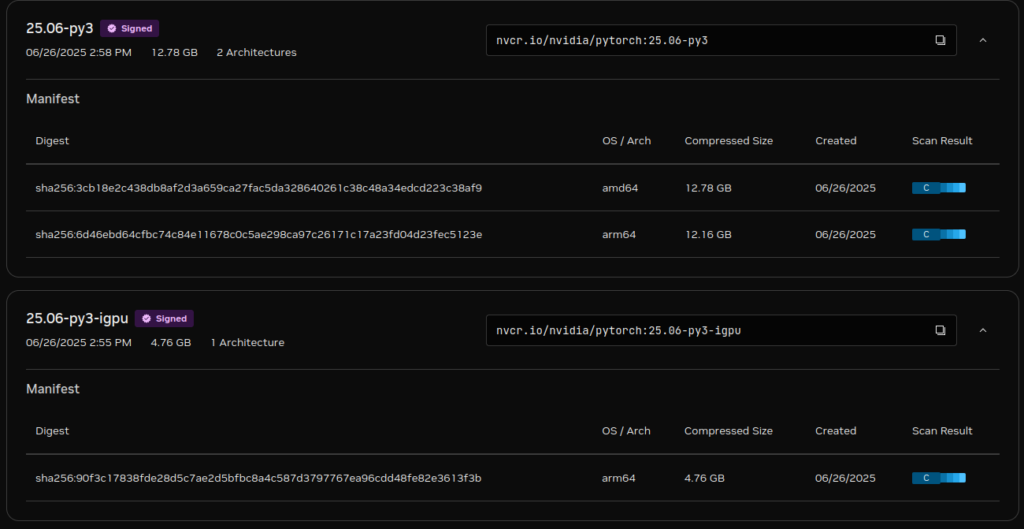
igpu版本只针对arm64架构,正是我们所需要的。
2. Python后端与容器启动
下载好模型后,需要写一个后端来运行模型,实例代码可以参考https://www.modelscope.cn/models/Qwen/Qwen3-Reranker-8B和www.heywhale.com/mw/notebook/6864f7354a5c763e5c47242f。这里给出我的后端代码,为了与知识库查询接口对齐,配置了请求体和响应体的格式:
"""
如何在 LightRAG 中调用
在你的 .env 文件中配置:
RERANK_TYPE=cohere
COHERE_API_KEY=your_dummy_key_or_leave_empty_if_not_required
RERANK_BASE_URL=http://localhost:xxxx/rerank
或者在代码中直接调用:
from lightrag.rerank import cohere_rerank
results = await cohere_rerank(
query="What is the capital of France?",
documents=["Paris is the capital.", "Tokyo is in Japan.", "London is big."],
top_n=2,
base_url="http://localhost:xxxx/rerank",
api_key=None, # 如果你的 API 不需要 key,可设为 None
model="qwen-reranker" # 任意字符串,会被忽略但必须存在
)
注意:如果你的 API 不需要 API Key,请确保 LightRAG 调用时 api_key=None,否则会发送 Authorization: Bearer ... 头,可能导致 403。你也可以在 FastAPI 中忽略该头。
"""
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import List, Optional
import uvicorn
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
# ==================== 配置 ====================
RERANKER_MODEL_PATH = os.path.expanduser('/home/models')
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
MAX_LENGTH = 4096
# ==================== 全局变量 ====================
tokenizer = None
model = None
token_false_id = None
token_true_id = None
# ==================== 数据模型 ====================
class RerankRequest(BaseModel):
model: Optional[str] = None # LightRAG 会发送此字段
query: str
documents: List[str]
top_n: Optional[int] = None # 注意:必须是 top_n
class Config:
extra = "allow" # 允许 extra_body 中的额外参数
class RerankResult(BaseModel):
index: int
relevance_score: float
class RerankResponse(BaseModel):
results: List[RerankResult]
# ==================== 辅助函数 ====================
def format_instruction(instruction: str, query: str, doc: str) -> str:
if instruction is None:
instruction = 'Given a web search query, retrieve relevant passages that answer the query'
return f"<|im_start|>system\n{instruction}<|im_end|>\n<|im_start|>user\n<Query>: {query}\n<Document>: {doc}<|im_end|>\n<|im_start|>assistant\n"
def process_inputs(pairs):
inputs = tokenizer(
pairs,
padding=True,
truncation=True,
return_tensors="pt",
max_length=MAX_LENGTH,
add_special_tokens=False # 根据 Qwen tokenizer 行为调整
)
return inputs.to(model.device)
@torch.no_grad()
def compute_scores(pairs):
inputs = process_inputs(pairs)
last_token_logits = model(**inputs).logits[:, -1, :]
true_logits = last_token_logits[:, token_true_id]
false_logits = last_token_logits[:, token_false_id]
scores_tensor = torch.stack([false_logits, true_logits], dim=1)
probabilities = torch.nn.functional.softmax(scores_tensor, dim=1)
yes_probabilities = probabilities[:, 1].cpu().tolist()
return yes_probabilities
# ==================== FastAPI App ====================
app = FastAPI(title="Qwen Reranker API (Cohere-compatible)", version="1.0.0")
@app.on_event("startup")
async def startup_event():
global tokenizer, model, token_false_id, token_true_id
print(f"Loading reranker model from: {RERANKER_MODEL_PATH}")
if not os.path.isdir(RERANKER_MODEL_PATH):
raise RuntimeError(f"Model path not found: {RERANKER_MODEL_PATH}")
try:
tokenizer = AutoTokenizer.from_pretrained(
RERANKER_MODEL_PATH,
padding_side='left',
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
RERANKER_MODEL_PATH,
torch_dtype="auto",
trust_remote_code=True
).to(DEVICE).eval()
token_false_id = tokenizer.convert_tokens_to_ids("no")
token_true_id = tokenizer.convert_tokens_to_ids("yes")
if token_false_id == tokenizer.unk_token_id or token_true_id == tokenizer.unk_token_id:
raise ValueError("'no' or 'yes' token not found in tokenizer vocabulary.")
print("✅ Model loaded successfully!")
except Exception as e:
print(f"❌ Model loading failed: {e}")
raise RuntimeError(f"Model loading failed: {e}")
@app.post("/rerank", response_model=RerankResponse)
async def rerank_documents(request: RerankRequest):
try:
task = 'Given a web search query, retrieve relevant passages that answer the query'
pairs = [format_instruction(task, request.query, doc) for doc in request.documents]
scores = compute_scores(pairs)
# 构建带索引的结果并排序
results_with_indices = [(idx, score) for idx, score in enumerate(scores)]
results_with_indices.sort(key=lambda x: x[1], reverse=True)
# 应用 top_n(如果指定)
if request.top_n is not None:
results_with_indices = results_with_indices[:request.top_n]
response_results = [
RerankResult(index=idx, relevance_score=score)
for idx, score in results_with_indices
]
return RerankResponse(results=response_results)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Rerank error: {str(e)}")
@app.get("/health")
async def health_check():
return {"status": "healthy", "model_loaded": model is not None}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=xxxx)将这个后端文件放到下载的pytorch容器中,并注意需要挂载模型路径。然后可以修改pip源来加速库安装:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config set install.trusted-host mirrors.aliyun.com
pip install torch transformers sentence-transformers accelerate fastapi uvicorn安装好库后,就可以启动这个后端了,再把整个容器重新打包成了一个docker镜像。
新的镜像容器启动采用了compose的方式,注意必须加runtime: nvidia,否则不会调用GPU,还是用的CPU,慢的一批:
services:
qwen_reranker:
# 镜像地址
image: qwen-reranker:pytorch_arm
# 容器启动后执行的命令
# 格式:["可执行文件", "参数1", "参数2"]
command: ["python", "/home/reranker_api.py"]
# 始终重启策略 (除非手动停止)
restart: always
# 端口映射: 宿主机端口:容器端口
ports:
- "28080:28080"
# 卷挂载: 宿主机路径:容器路径
volumes:
- /data/models_reranker:/home/models
# GPU 资源配置
runtime: nvidia
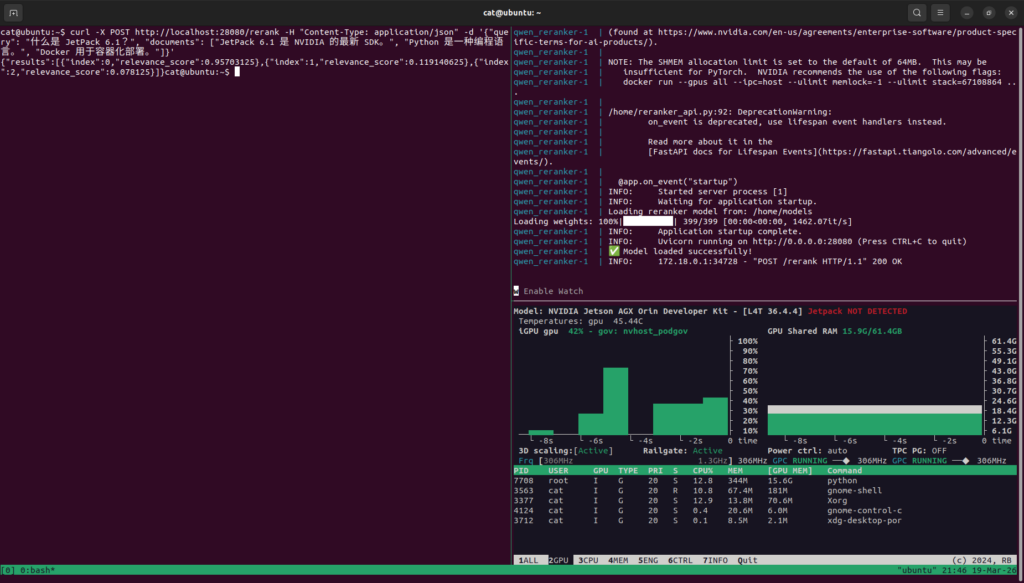
运行后,通过curl命令可以测试这个后端,可以看出igpu有运行,共享显存也有占用,且回复速度特别快,说明确实是在GPU上运行的。如果出现了curl了以后,半天没有回复,且显存占用很低,说明是用的CPU在跑,需要检查一下参数和torch运行情况。